最近有一个观点在 AI 社区流传:文件系统是 AI 最 Native 的形式。理由听起来很直观——Agent 直接读写文件,没有 SQL,没有连接池,没有事务管理,简洁优雅。
但这个观点有一个致命的缺陷:它只在单 Agent、简单场景下成立,在多 Agent 协作的真实世界中必然崩溃。
更重要的是,用文件系统不是”轻量”,而是”偷懒”。你最终会在应用层把数据库重新发明一遍,只不过发明得更烂。
第一部分:表面的”Native”与深层的幻觉
对于单个 Agent 操作简单数据的场景,文件系统确实显得”Native”:
1 | data = read_json_file("data.json") |
这个流程简洁、直观。文件系统还有其他优势:灵活的数据模型、与 Git 天然集成、几乎零运维成本。
在这个层面上,说”文件系统是 AI Native 的”似乎是对的。
但这只是幻觉。
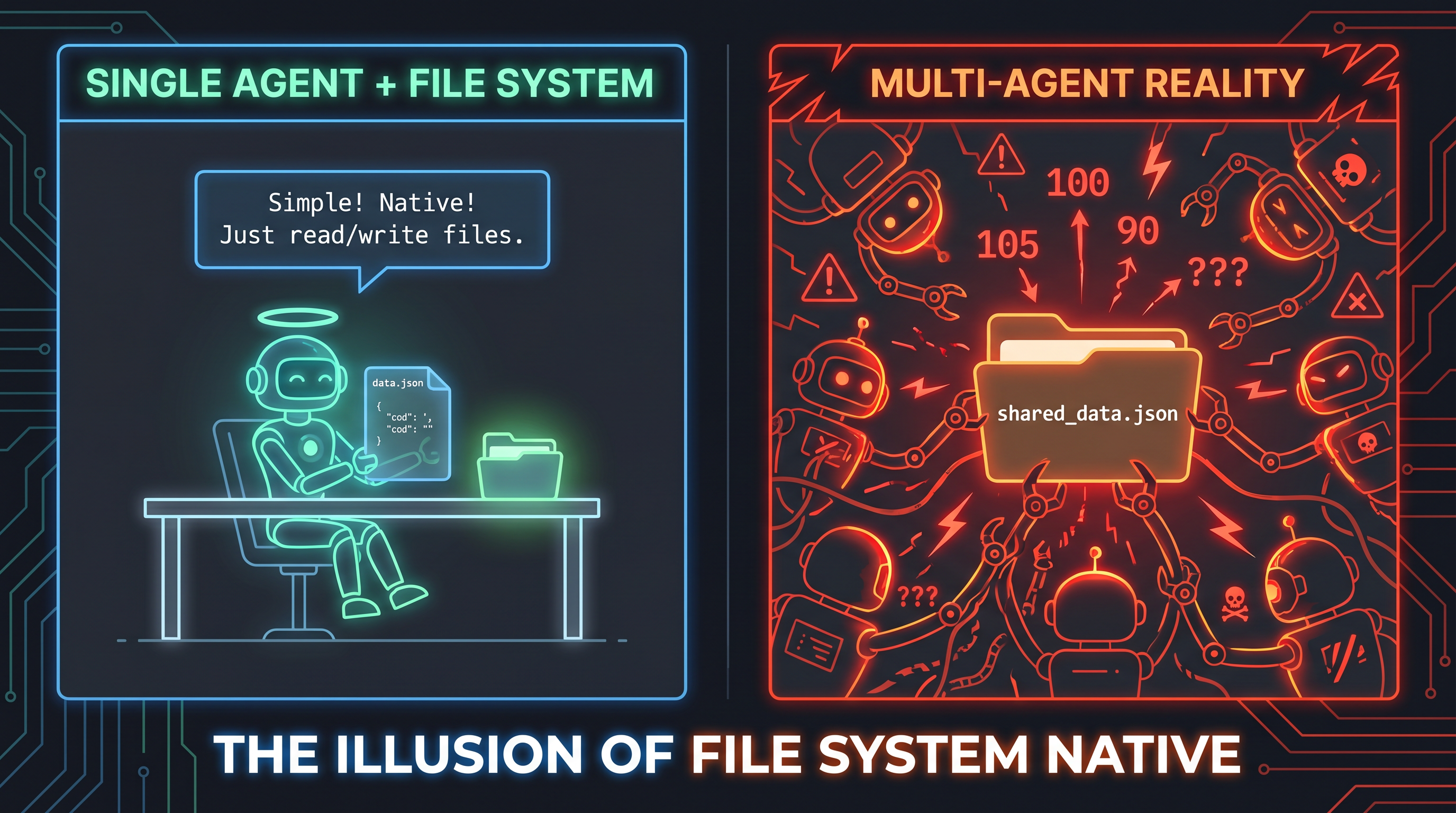
一旦系统变得稍微复杂一点——多个 Agent、并发操作、多源数据——文件系统就会暴露出根本性的缺陷。而这些”稍微复杂一点”的场景,正是现实中的常态。
第二部分:多 Agent 系统的真实困境
从 100 个 Agent 开始崩溃
2026 年初,一篇深度技术文章描述了一个令人震惊的发现:当多个 Agent 共享文件系统时,系统在大约 100 个 Agent 左右开始出现灾难性的失效。
这不是巧合。作者指出:”这是操作速率超过状态传播速率的临界点”。
丢失更新:一个无法绕过的灾难
让我们看一个真实的例子:一个电商系统,多个 Agent 并行处理订单。
1 | 初始库存:100 件商品 |
正确结果应该是某个确定的值,实际结果是完全不确定。这就是丢失更新(Lost Update)问题。
文件系统提供的并发控制机制极其原始:
- 整文件锁定:所有 Agent 排队等待,完全无法并行
- 无锁写入:允许并发,但导致数据竞争和不一致
这两个极端都不可接受。
第三部分:ACID 事务的必然性
原子性的缺失
Agent 需要同时更新多个相关数据时,文件系统无法保证原子性。
1 | 处理一个订单,需要同时更新: |
数据库的事务确保原子性——要么全部成功,要么全部回滚:
1 | BEGIN TRANSACTION |
隔离性的需求
LLM 的决策有延迟(通常 2-5 秒)。在这段时间里,其他 Agent 可能已经修改了数据。Agent 基于陈旧的、不一致的快照做出决策,是文件系统无法解决的根本问题。
数据库通过 MVCC(多版本并发控制) 为每个事务提供一致的数据快照,彻底解决这个问题。
第四部分:查询性能的悬崖
Agent 需要在 100 万条记录中找到特定客户的所有订单:
| 方式 | 操作 | 耗时 |
|---|---|---|
| 文件系统 | 加载整个 GB 级 JSON 文件,全量遍历 | 秒级~分钟级 |
| 数据库 | SELECT * FROM orders WHERE customer_id = 123 |
毫秒级 |
在多 Agent 系统中,这种查询会每秒发生数百次。文件系统的 I/O 瓶颈会让整个系统陷入停滞。
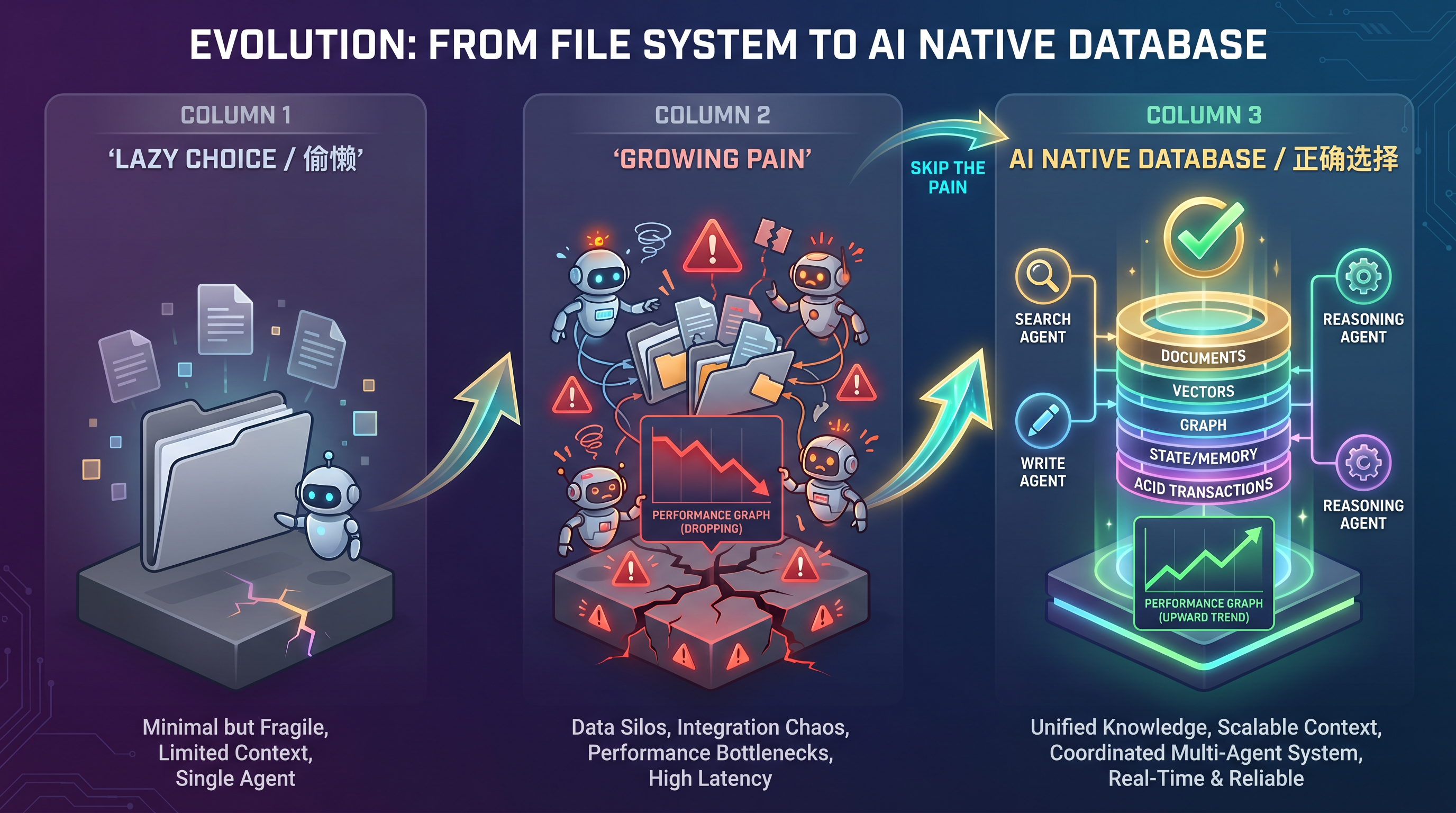
第五部分:从”支撑不住”到”必然演进”
这不是一个”选择”问题,而是一个必然问题。
1 | 阶段 1:单 Agent + 简单场景 |
文件系统是为”单用户、单进程、离线”设计的。数据库是为”多用户、多进程、在线、高并发”设计的。当 Agent 系统从前者演进到后者时,不是”选择升级”,而是”被迫升级”。
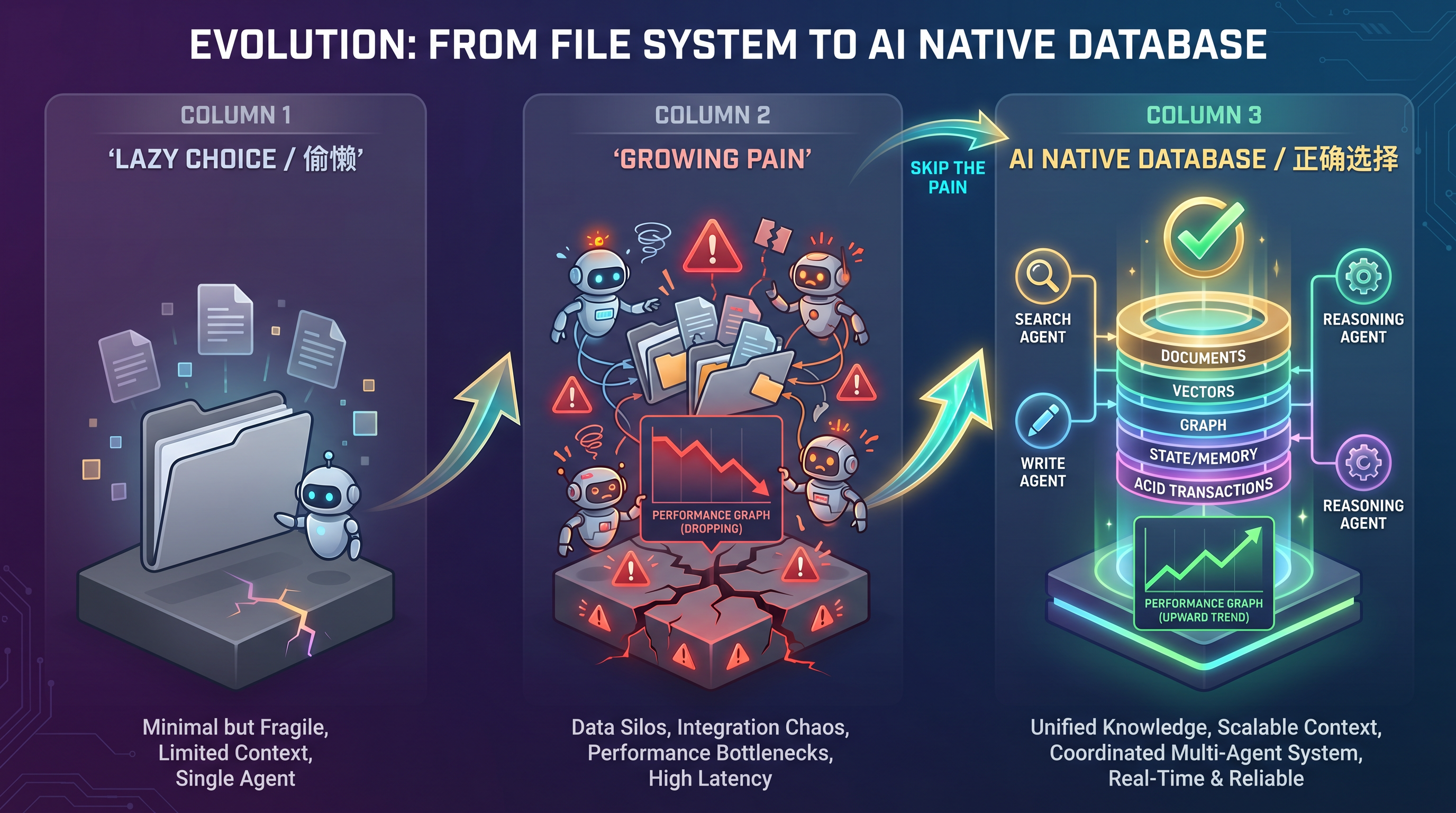
结论:数据库里存文档,完全合理
“AI Native”不应该理解为”最简单的”,而应该理解为”最适合 AI 系统需求的“。
有人担心数据库太重。但现代 AI Native 数据库(如 Weaviate、Qdrant、TiDB 等)已经支持在同一个系统里存储:
- 文档(JSON、Markdown、非结构化文本)
- 向量(Embedding,用于语义搜索)
- 图关系(知识图谱、Agent 之间的依赖)
- 状态与记忆(短期上下文、长期知识)
- ACID 事务(保证一致性)
在数据库里存文档,不是妥协,而是正确的架构选择。
最后的讽刺:如果坚持用文件系统支撑多 Agent 系统,最终会在应用层重新发明数据库的所有功能——并发控制、事务管理、索引、缓存……只不过发明得更烂、更难维护、更容易出 bug。
与其这样,不如从一开始就选择真正为 Agent 设计的存储方案——AI Native 数据库。
参考资料
- The Speedcraft Lab. (2026). Multi Agent State Sync When a Thousand AI Agents Share One World. Medium.
- Anthropic. (2025). How we built our multi-agent research system.
- ApX Machine Learning. (2026). Limitations of File-Based Storage.